A real-world case study using YOLOv5, PyTorch, and a custom CNN to analyze traffic conditions from Puerto Rico’s DTOP webcam system.
Round 1: Object Detection — YOLOv5
Getting started without a pile of labeled data can make building models difficult. To begin
collecting useful training images of San Juan traffic, we leveraged webcams published by
DTOP Puerto Rico.
Rather than manually labeling thousands of frames, we used the excellent YOLOv5 model from
ultralytics/yolov5. It performs extremely well at detecting the objects we care about:
cars, buses, and trucks.
Below is the initial object detection pipeline in PyTorch:
import json
from PIL import Image
import numpy as np
import torch
import time
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Load YOLOv5
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True).to(device)
# DTOP webcam routes
sj1 = ("http://its.dtop.gov.pr/images/cameras/26-0.1_01_MD-IPV.jpg",
"http://its.dtop.gov.pr/en/TrafficImage.aspx?id=119&Large=1",
10, 25, 18.458339088897567, -66.08570387019088)
# … additional cameras …
def printTraffic(carCount, route):
if carCount == 0:
return "no traffic"
if carCount < route[2]:
return "low traffic"
if carCount < route[3]:
return "medium traffic"
return "high traffic"
# Loop every 60 seconds and evaluate
while True:
finalResult = []
for route in sjOriRoutes:
results = model(route[0])
counts = results.pandas().xyxy[0].name.value_counts()
vehicleCount = counts.get("car", 0) + counts.get("bus", 0) + counts.get("truck", 0)
res = printTraffic(vehicleCount, route)
results.render()
fileName = "static/img/" + route[0].split('/')[-1]
Image.fromarray(results.imgs[0]).save(fileName)
finalResult.append((fileName, route[0], route[1], route[2], route[3],
vehicleCount, res, route[4], route[5]))
with open('latest.json', 'w') as outfile:
json.dump(finalResult, outfile, cls=NpEncoder)
time.sleep(60)
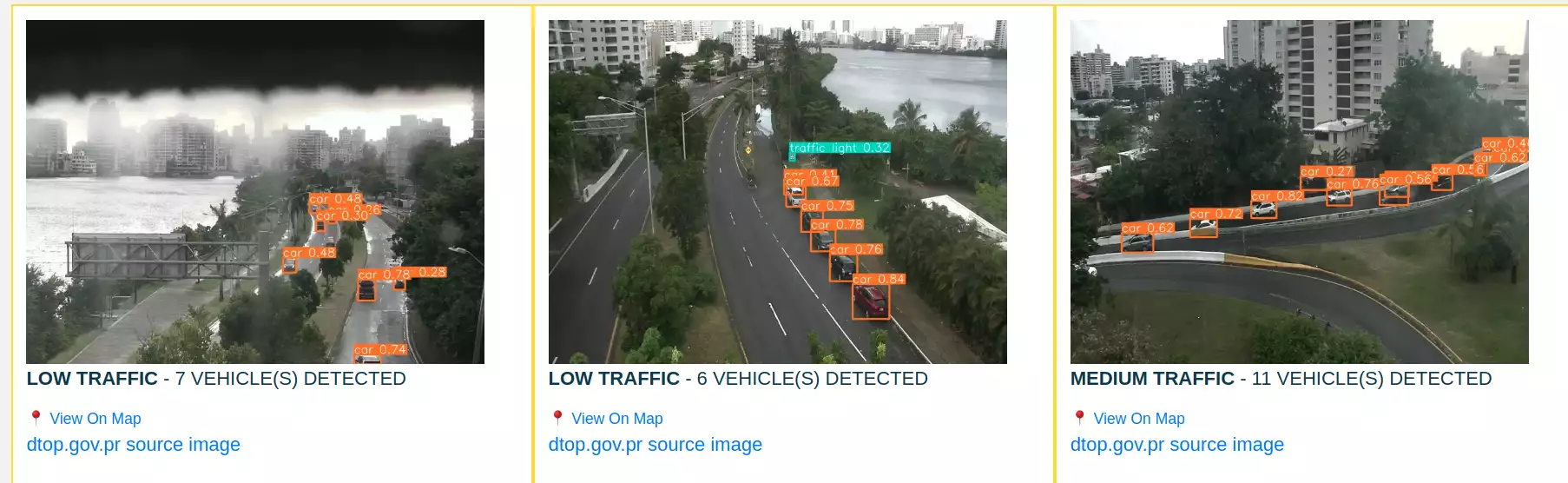
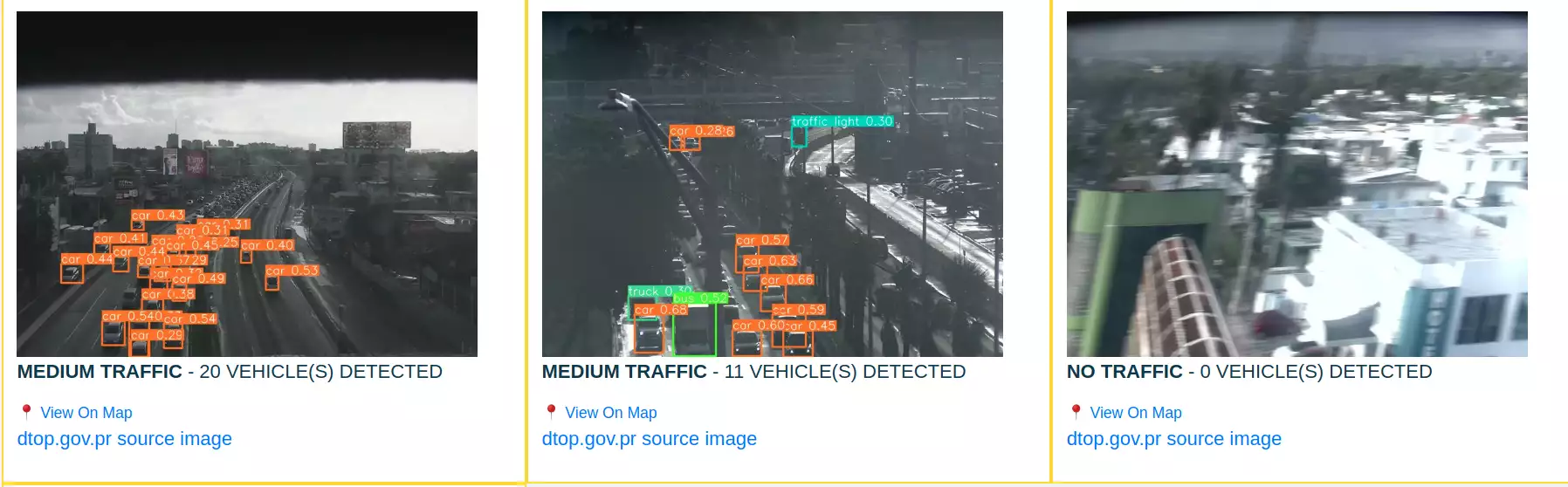
Limitations of Pure Object Detection
YOLOv5 is powerful, but DTOP webcams introduce challenges:
- Low resolution and compression artifacts
- Nighttime images are too dark for object detection
- Heavy traffic often becomes a wall of headlights
- Camera angles sometimes obscure vehicles
As a result, medium or heavy traffic was sometimes incorrectly labeled as “low” or even “no traffic.”
At night, YOLOv5 occasionally detected zero vehicles in gridlocked conditions.
Here’s an example of YOLOv5 detections:
Round 2: A Holistic Approach (Full-Frame Classification)
Humans don’t count cars one by one—we look at the entire image and immediately understand
traffic conditions. So instead of relying on object counts, we built a custom CNN classifier
trained to look at the full frame and categorize traffic directly.
To bootstrap training data, we used YOLOv5 to generate initial labels, saved all images into
folders, then manually corrected misclassified images.
Data collection script:
def getFolder(carCount, route):
if carCount == 0:
return "no"
if carCount < route[2]:
return "low"
if carCount < route[3]:
return "medium"
return "high"
while True:
for route in sjOriRoutes:
results = model(route[0])
counts = results.pandas().xyxy[0].name.value_counts()
vehicleCount = counts.get("car", 0) + counts.get("bus", 0) + counts.get("truck", 0)
folder = getFolder(vehicleCount, route)
fileName = "results/" + folder + "/" + time.strftime("%Y%m%d%H%M") + route[0].split('/')[-1]
Image.fromarray(results.imgs[0]).save(fileName)
time.sleep(60)
After collecting several thousand images across conditions—day, night, rush hour—we manually curated
the dataset to improve label quality.
Training a Custom Convolutional Neural Network
We built a simple CNN to classify images into: no / low / medium / high traffic.
Model training code excerpt:
class ConvNet(nn.Module):
def __init__(self, num_classes=4):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 36, 3, padding=1)
self.bn1 = nn.BatchNorm2d(36)
self.pool = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(36, 20, 3, padding=1)
self.conv3 = nn.Conv2d(20, 32, 3, padding=1)
self.bn3 = nn.BatchNorm2d(32)
self.fc = nn.Linear(75*75*32, num_classes)
def forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x))))
x = F.relu(self.conv2(x))
x = F.relu(self.bn3(self.conv3(x)))
x = x.view(-1, 75*75*32)
return self.fc(x)
Trained over 30 epochs, the model reached high accuracy and generalized far better at night and
during heavy traffic.
Integrating the Model Into Production
cp = torch.load("best.model")
evalModel = ConvNet()
evalModel.load_state_dict(cp)
evalModel.eval()
evalModel.to("cuda")
while True:
finalResult = []
for route in sjOriRoutes:
response = requests.get(route[0])
image = Image.open(BytesIO(response.content))
tensor = inputTransform(image).unsqueeze(0).cuda()
output = evalModel(tensor)
_, predicted = torch.max(output, 1)
label = idx2class[predicted.item()]
fileName = "static/img/" + route[0].split('/')[-1]
finalResult.append((fileName, route[0], route[1], 0, 0, 0, label, route[4], route[5]))
image.save(fileName)
with open('latest.json', 'w') as f:
json.dump(finalResult, f, cls=NpEncoder)
time.sleep(60)
These classifications now power
San Juan Puerto Rico Traffic,
giving a near real-time view of traffic flow.
What’s Next?
We plan to:
- Automate daily training using newly collected webcam frames
- Continuously improve the CNN accuracy
- Replace YOLOv5 entirely with the learned holistic model
- Self-correct noisy labels to improve dataset quality
This will eventually create a system where the model improves itself over time.
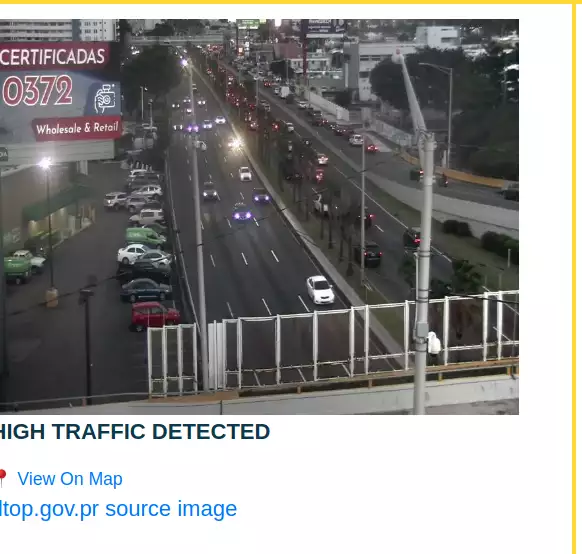
Example Classifications

Happy Hacking!